Problema de negócio
Uma empresa de Seguros possui um sistema inflexível, onde é impossível aceder a dados de cadastro de clientes categorizados por sector de atividade. O Sistema também não prevê validação de campo, permitindo ao técnico de cadastro efetuar aberturas de clientes de modo não padronizado.
Solução
A solução técnica rápida e confiável consistiu em carregar um ficheiro .csv contendo as classificações e normalizações necessárias, para alimentar e enriquecer os dados disponíveis no Datalake a partir da integração com o sistema da empresa de Seguros.
Assim sendo, foi criado o seguinte fluxo:
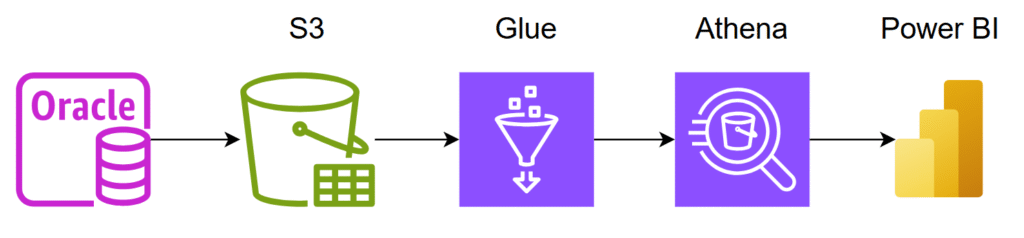
Img. 01 – Fluxograma simplificado
A Base de Dados Oracle está conectada ao Data Lake onde foram criados os buckets. No bucket datalake-autorizador foi criada a pasta CENSUS_CLASSIFICACAO, onde carrega-se o ficheiro apoio_census.cvs.
S3://data-autorizador/CENSUS_CLASSIFICACAO/

Img. 02 – Pastas organizacionais do Bucket S3
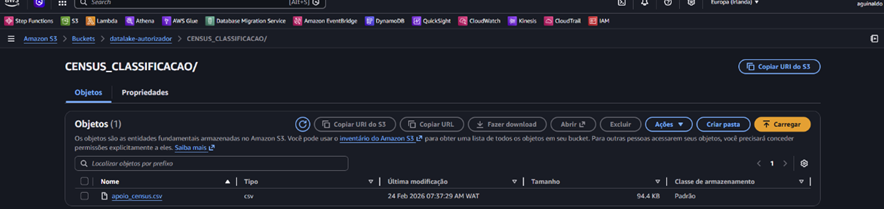
Img. 03 – Ficheiro .csv carregado
Após o carregamento do .csv, se corre o job Glue.
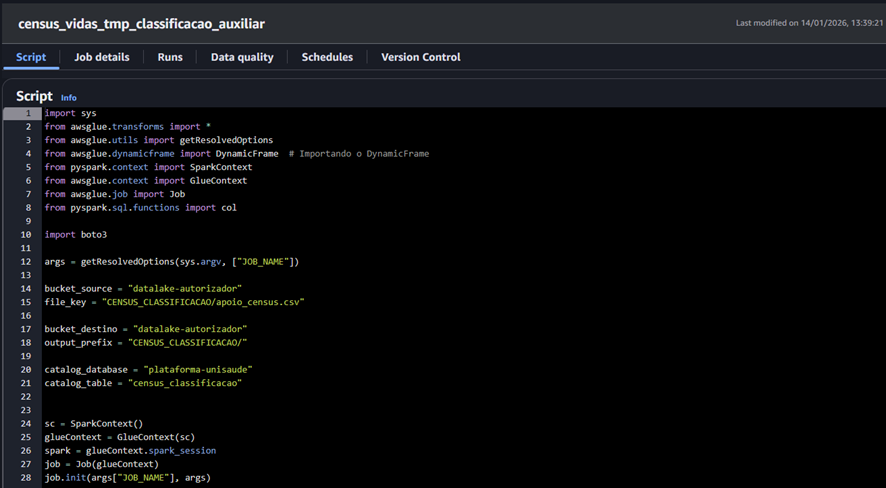
Img. 04 – Script do job census_vidas_tmp_classificacao_auxiliar
Este job cria os ficheiros parquet que ficam salvos na pasta census_classificacao/ dentro do S3.
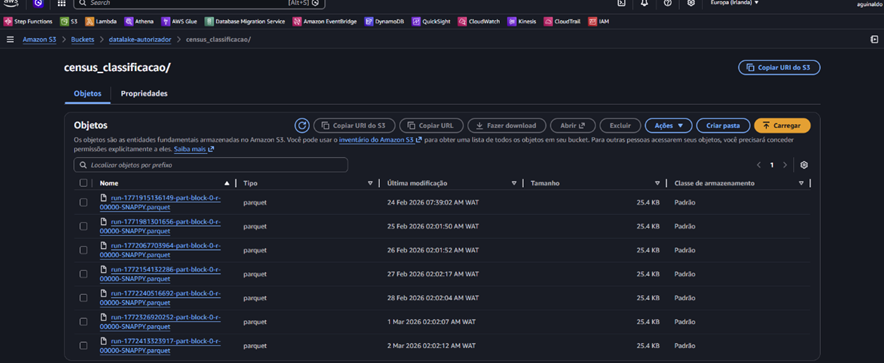
Img. 05 – Ficheiros parquet
Uma vez criada a tabela de apoio denominada census_classificacao já é possível escrever a query no Athena, para o enriquecimento dos dados presentes na view denominada vw_census_vidas_tmp.
SELECT
vw_census_vidas_tmp.apolice AS ID
,vw_census_vidas_tmp.empresa AS COMPANY
,vw_census_vidas_tmp.inicio_vigencia AS CONTRACT_START
,vw_census_vidas_tmp.fim_vigencia AS CONTRACT_END
--,COUNT (vw_census_vidas_tmp.exposicaohoje) AS Vidas
,census_classificacao.empresa AS REVIEWED_COMPANY
,census_classificacao.setoratividadeempresa AS SECTOR
,census_classificacao.tipocontrato AS CONTRACT_TYPE
FROM vw_census_vidas_tmp
LEFT JOIN census_classificacao ON vw_census_vidas_tmp.apolice = census_classificacao.apolicemit
WHERE
vw_census_vidas_tmp.situacao_beneficiario = 'Ativo' AND vw_census_vidas_tmp.situacao_da_apolice = 'Ativa'
GROUP BY
vw_census_vidas_tmp.apolice
,vw_census_vidas_tmp.empresa
,vw_census_vidas_tmp.inicio_vigencia
,vw_census_vidas_tmp.fim_vigencia
,census_classificacao.empresa
,census_classificacao.setoratividadeempresa
,census_classificacao.tipocontrato
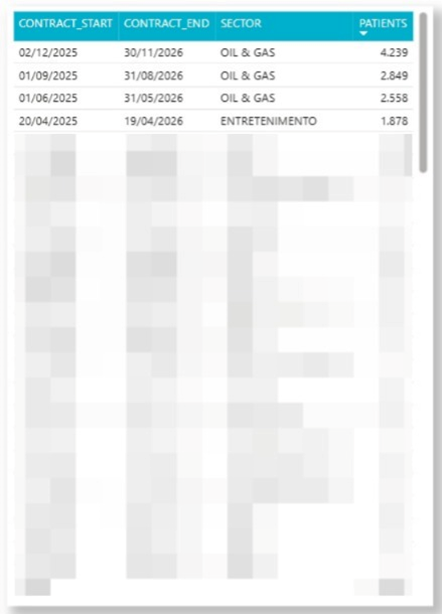
ORDER BY tipocontrato DESCCriando uma view a partir da query acima, se consegue a partir do ODBC conectar os dados ao Power BI e montar visuais já normalizados e enriquecidos. Por questões de privacidade de dados apresentaremos apenas o quadro central extraído do dashboard Power BI.
Conclusão
- Implementado pipeline de dados escalável, com recurso a AWS Glue para conversão de volumes de dados CSV para Parquet.
- Redução de 70% no volume de dados processados.
- Estruturação de queries otimizadas no Amazon Athena para servir de base para relatórios gerenciais.
- Conexão do ecossistema AWS ao Power BI via ODBC, permitindo a visualização de KPIs em tempo real para a tomada de decisão.









